

MRI-TIMIT: a Multimodal Real-Time MRI Articulatory Corpus
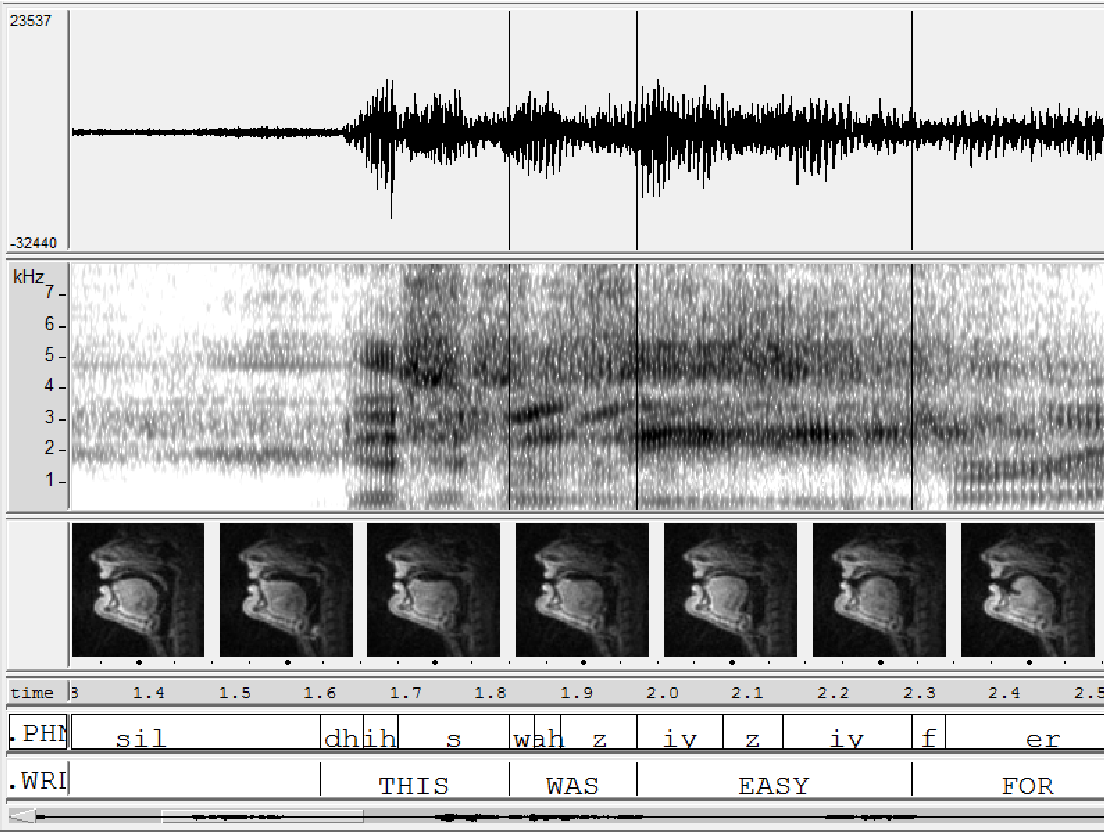
MRI-TIMIT is a large-scale database of synchronized audio and real-time magnetic resonance imaging (rtMRI) data for speech research. The database currently consists of midsagittal upper airway MRI data and phonetically-transcribed companion audio, acquired from two male and two female speakers of American English.
MRI-TIMIT is now publicly available for research purposes as part of the broader USC-TIMIT database.
Subjects
| ID | Gender | Age | Birthplace |
|---|---|---|---|
| M1 | Male | 29 | Buffalo, NY |
| M2 | Male | 33 | Ann Arbor, MI |
| W1 | Female | 23 | Commack, NY |
| W2 | Female | 32 | Westfield, IA |
Corpus
The same 460-sentence phonetically balanced dataset used in the MOCHA-TIMIT corpus (Wrench 1999) was elicited from each subject.Articulatory Data
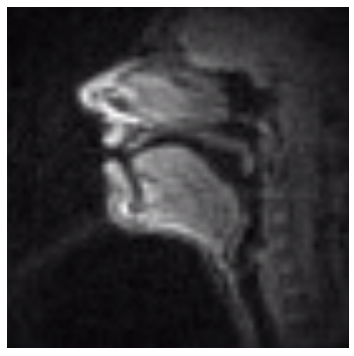
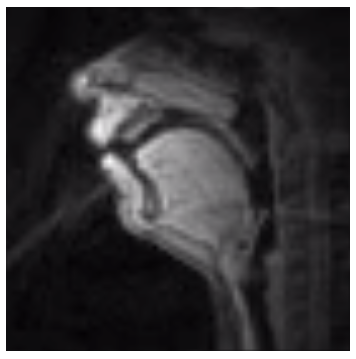
Subject's upper airways were imaged in the midsagittal plane using a custom real-time MRI protocol (Bresch et al. 2008). MRI data were acquired at Los Angeles County Hospital on a Signa Excite HD 1.5T scanner using a 13-interleaf spiral gradient echo pulse sequence (Tr = 6.164 msec, FOV = 200x200 mm, flip angle = 15deg). Image resolution: 68x68 pixels. Video rate = 23.18 frames/sec.Acoustic Data
Audio was simultaneously recorded at a sampling frequency of 20kHz inside the MRI scanner, using a custom fiber-optic microphone noise-cancelling system (Bresch et al. 2006) synchronized with the video signal through the scanner master clock. Time-aligned phonetic transcriptions of all utterances in the database were generated from the audio recordings, using the freely available tool SailAlign (Katsamanis et al. 2011).Example Utterances
|
Subject M1:
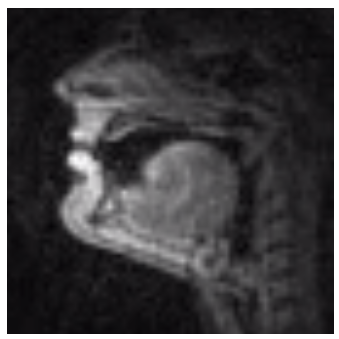
|
Subject M1:
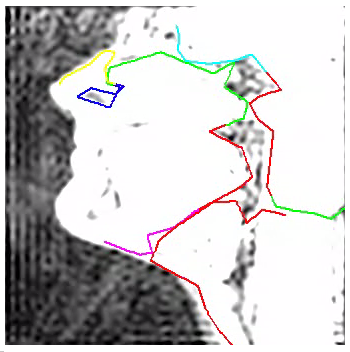
|
Subject M2:
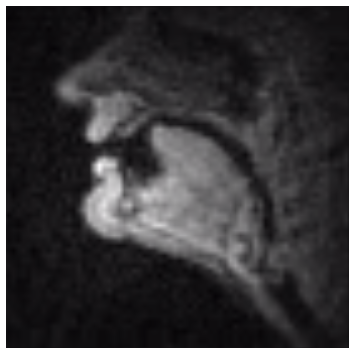
|
Subject W1:
|
Subject W2:
|