Introduction
The SpeechLinks project focuses on creating robust, widely-deployable and cost-effective technology solution for enabling and enhancing cross-lingual spoken language interaction between people who do not share a common language. One of our target applications focuses on communication between healthcare personnel who speak English only and patients with limited English proficiency (sponsored by the NSF). The interaction represents machine-mediated interpersonal communication, which is different from conventional human-machine dialogs.
The state-of-the-art in speech to speech (S2S) system design that enables such cross-lingual interactions is characterized by (1) a pipelined architecture of speech recognition, machine translation and speech synthesis that relies primarily on lexical information, largely ignoring other rich information present in speech and spoken discourse, (2) minimal interaction between the constituent components beyond the pipelining and (3) not adequately taking advantage of the humans in the loop for automatically learning, adapting and collaboratively managing the interaction just as an experienced interpreter would do. Overcoming these fundamental limitations requires improving robust intelligence at all levels - signal, system, and human - and directly leads to the research questions of this project.
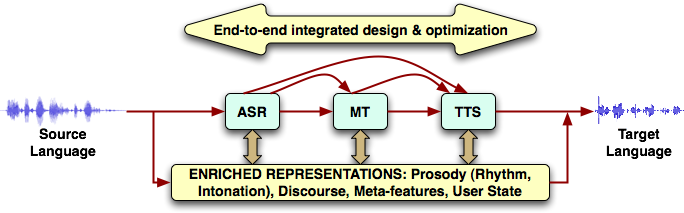
Our central premise is that the mediating system should utilize the rich context, beyond what is conveyed by words, while being cognizant of and working along with the participating humans for enabling successful cross-lingual interactions in terms of improved information transfer, communication efficiency and social co-presence. We propose to capture, model and transfer rich contextual information conveyed through speech prosody, discourse, and user state behavior to aid robust translation and expressive synthesis in the target language.
In addition to the above, the SpeechLinks team also works on the design and portability issues of S2S systems in collaboration with BBN Technologies as part of the DAPRA TRANSTAC program.
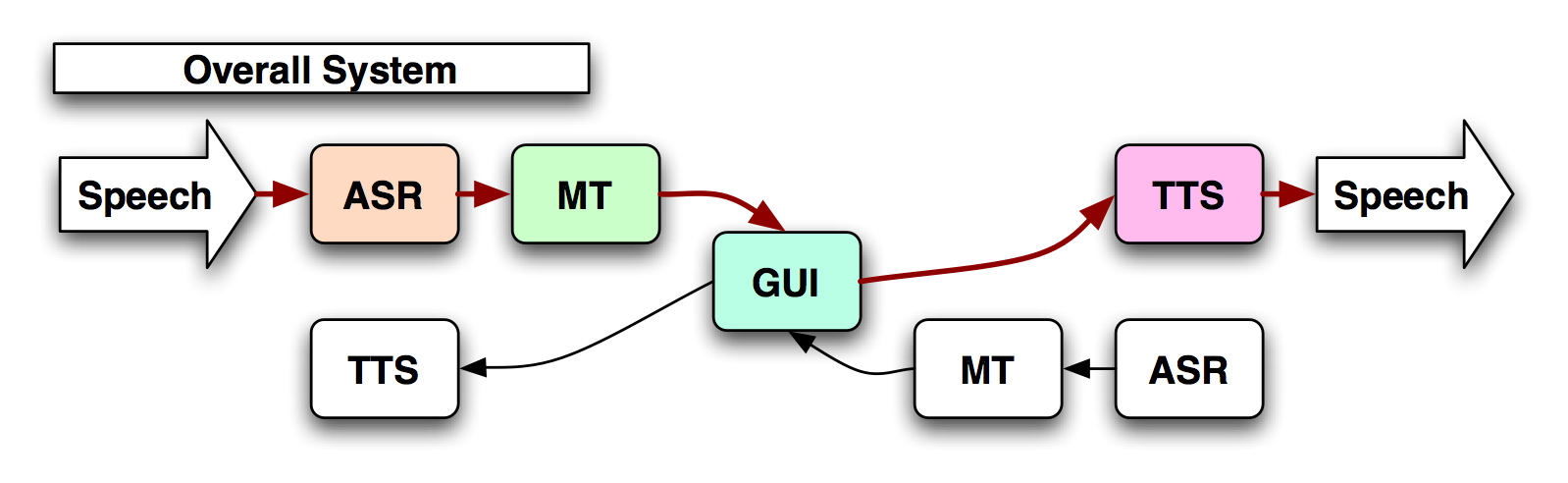
Top-level Overview of an S2S System
The SpeechLinks translation device operates by recognizing the user's speech input and converting it into text. The text is subsequently
translated, and re-synthesized back into the target language.
The Automatic Speech Recognition (ASR) subsystem that produces N-best
lists along with the decoding confidence scores. The ASR operates in
real time in the two languages of interest.
The ASR uses models of the acoustic patterns of human
speech trained by example recordings and statistical knowledge about
the structure of the language trained by example transcripts.
The Dialog Manager (DM) acts as the heart of the system, redirecting messages accordingly. Every output of the speech recognizer, tagged
with time stump, serial number, and other important information is
received by the DM, and usually is redirected for display to the
Graphical User Interface (GUI), and for translation to the Machine
Translation unit. However, the DM also has the options of rejecting
recognition results based on several factors, such as confidence
reported by the ASR.
The Machine Translation (MT) unit operates in two modes: The
classifier attempts to assign a concept to an utterance, so for
example a sentence such as "Umm and do you have any headaches" would
become the concept "Do you have a headache". The classifier can
perform really accurately in the case of utterances that are in
domain, in other words, for those sentences that we trained the system
exhaustively to work with. However out of
domain utterances are translated in a statistical manner by the
Statistical Machine Translation (SMT) unit. The SMT breaks the
sentence into segments and translates piece by piece, reconstructing
the result on the destination language.
Finally, a unit selection based Text To Speech synthesizer (TTS)
provides the spoken output. The TTS operates in several modes: for
utterance results of the classifier, the naturally sounding human
recording of the utterance is played out. If the utterance was
statistically classified, then the unit of the synthesizer drops from
the utterance level to the word level and a concatenation of words is
played out. Finally, for words that we have no human recordings of,
synthesis of the individual words, and of the sentence takes place at
the diphone level.
PEOPLE
SAIL Faculty
External Collaborators
- USC Annenberg School of Communication: Prof. Margaret McLaughlin
- USC Keck School of Medicine: Dr. Baezconde-Garbanati
- AT&T Research Labs: Dr. Srinivas Bangalore
- BBN Technologies: Dr. John Makhoul, Prem Natarajan, Rohit Prasad and Dr. Vivek Sridhar
SAIL Students
PUBLICATIONS
DEMO
An old version of the SpeechLinks system: low resolution (4.82MB)
or high resolution (35.8MB).
NEWS
- The first data collection for the NSF-sponsored "Context enriched speech-to-speech translation" was held on 30th January 2010 in the Electrical Engineering Building at USC.
- "The Doctor Can Understand You Now", US News and World Report Science, September 23, 2009.