“When” and “where” are the fundamental pillars of Computational media intelligence, for developing a holistic understanding of a scene which translates to locate the action of interest in the space and time. In this project, we develop a system to automatically detect the active speakers in space and time, specifically for media content.
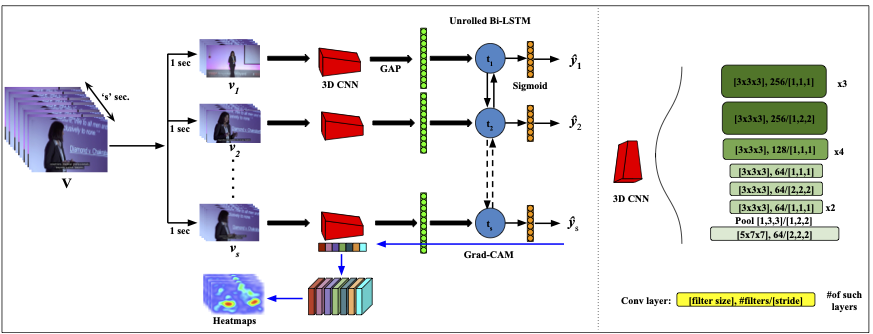
This work is inspired by our preliminary work [1], where we presented a cross-modal system for the task of voice activity detection by observing just the visual frames. We performed a thorough analysis and showed that the learned embeddings can locate the human bodies and faces. The cross-modal architecture is shown below: