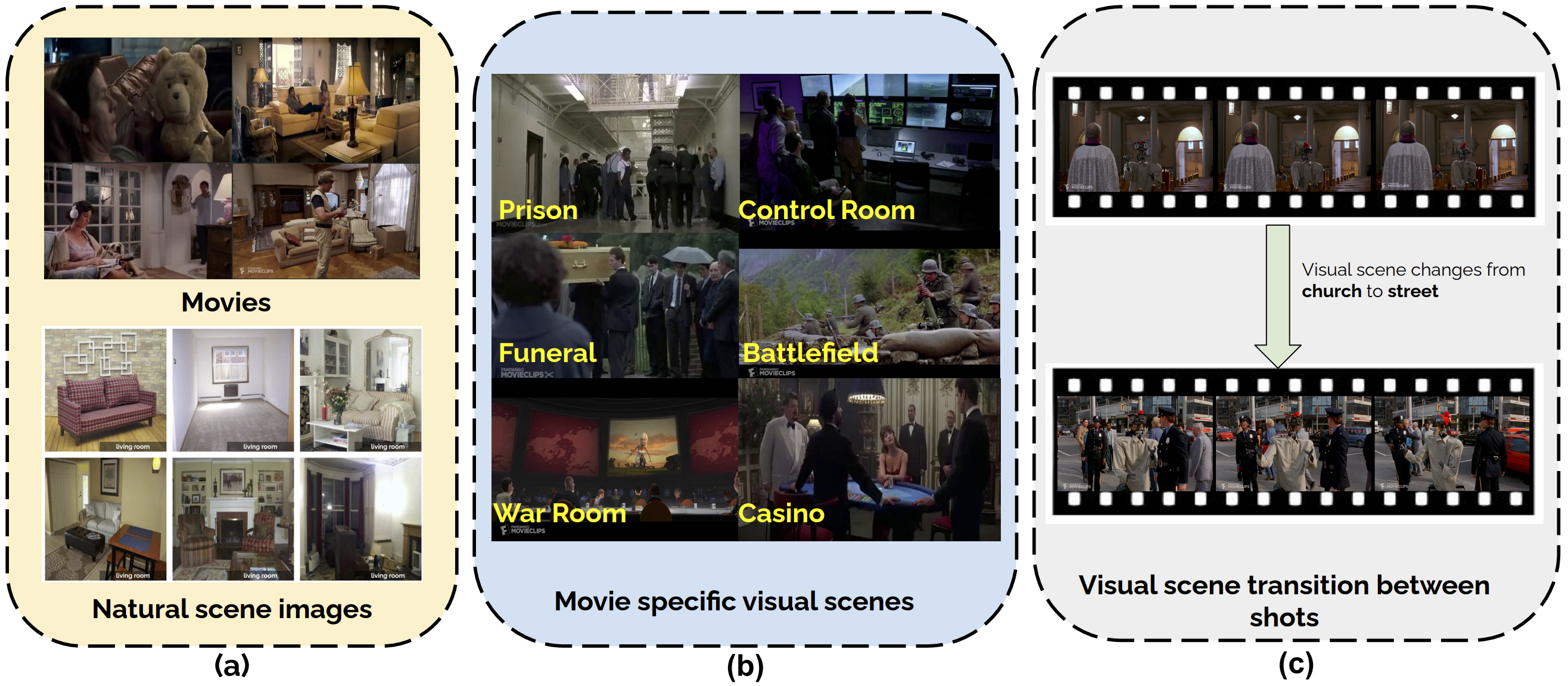
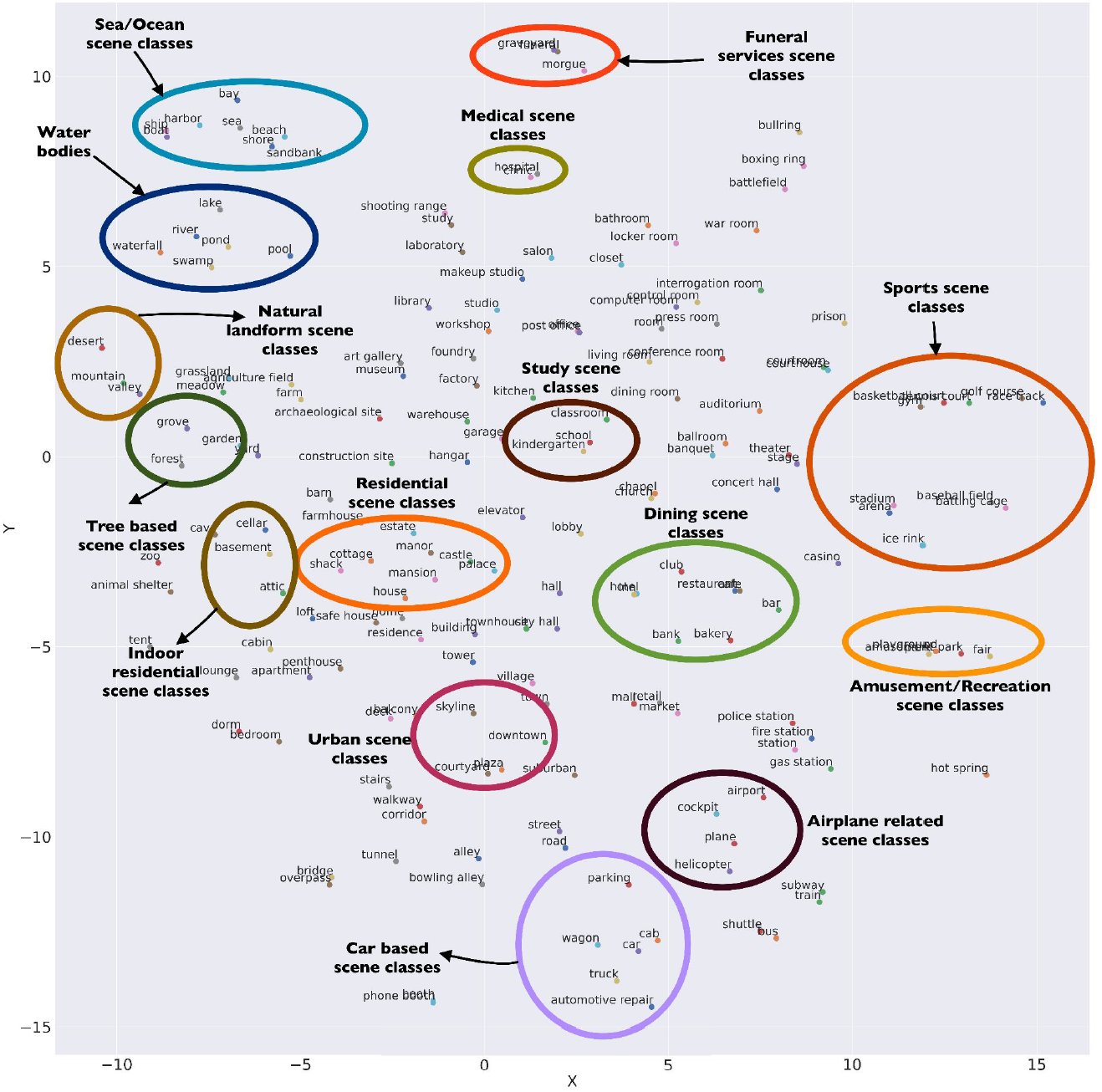
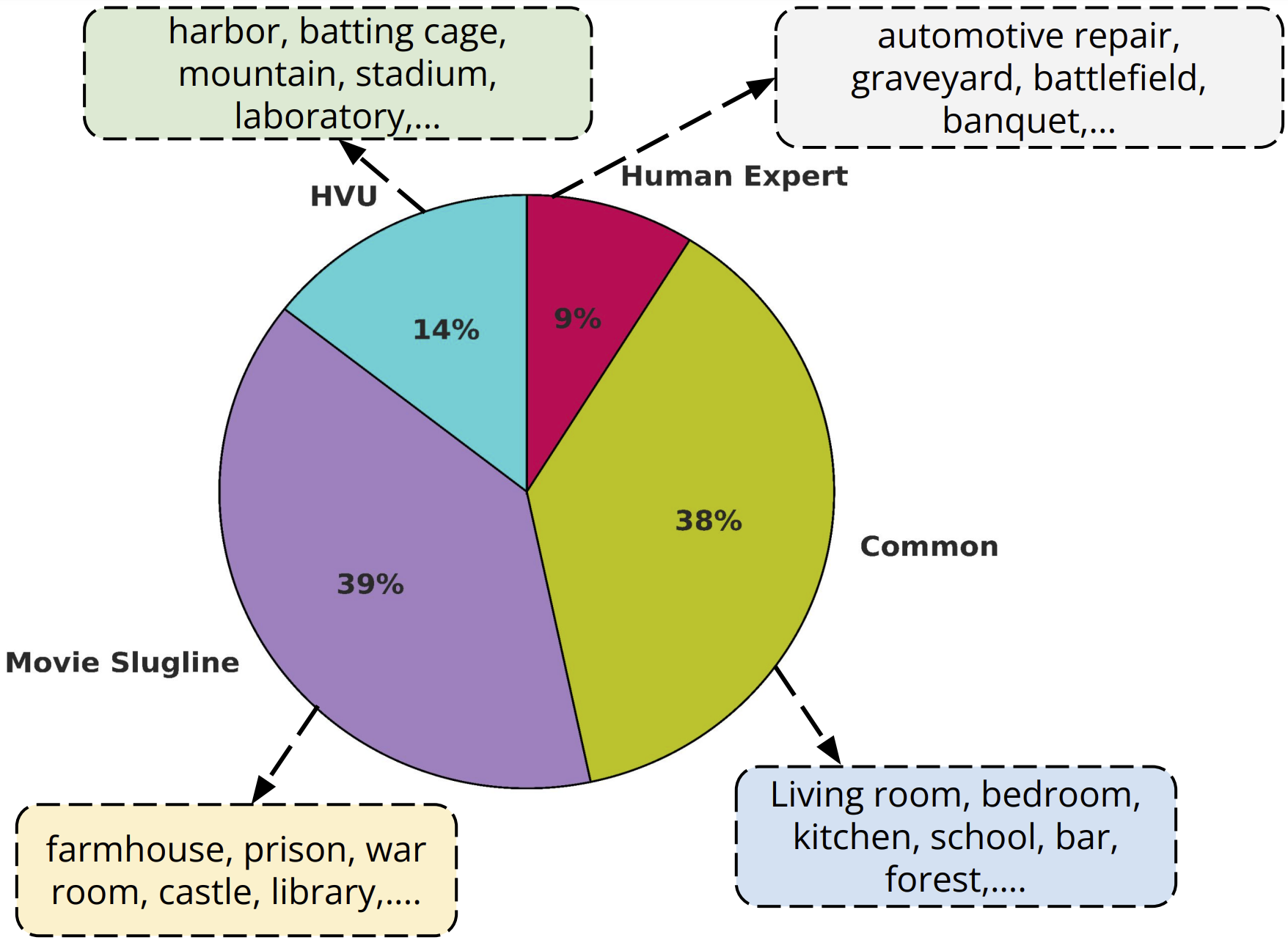
|
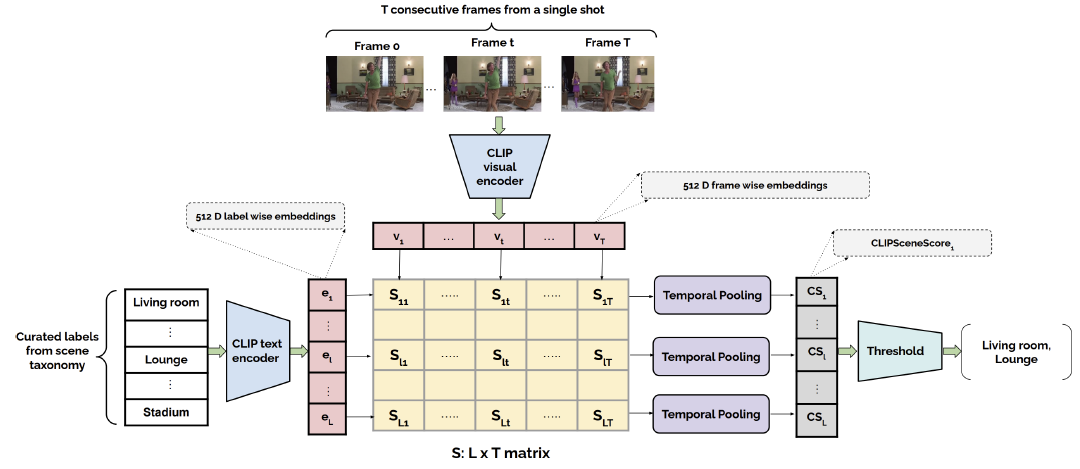
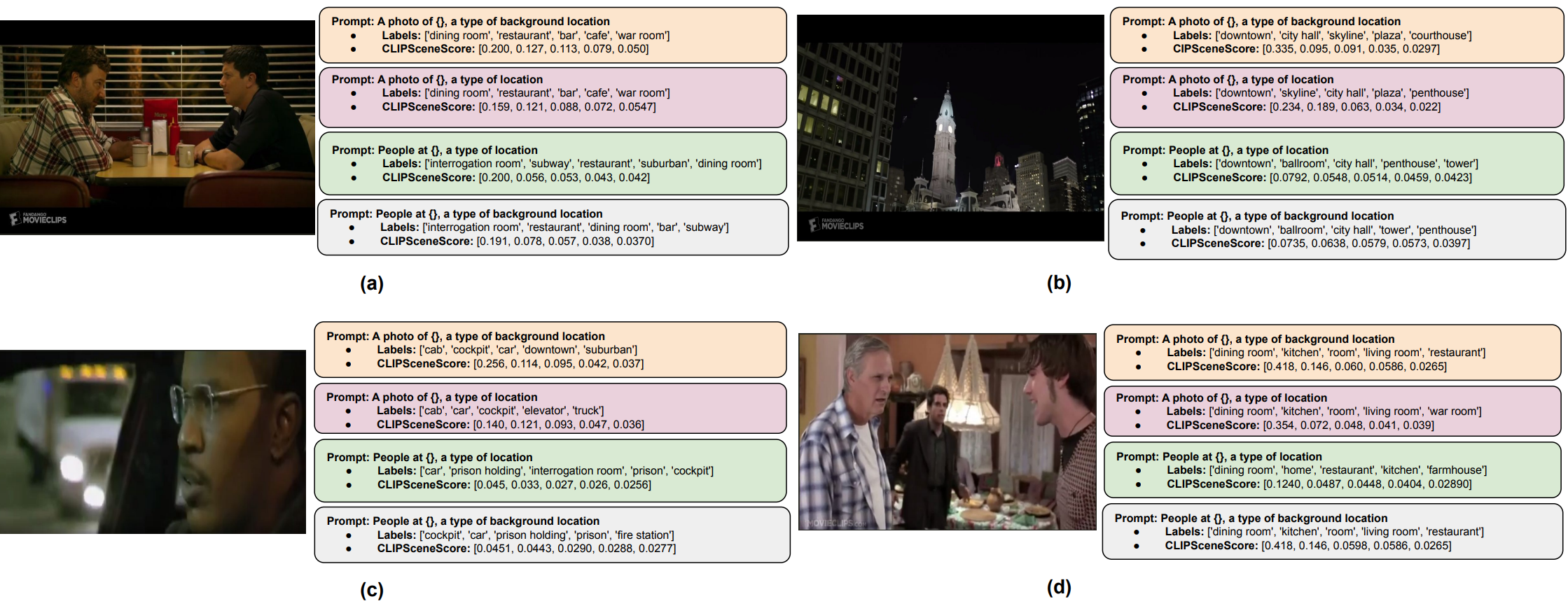
Overview of the CLIP based visual scene labeling pipeline is shown in the above figure. For tagging individual frames using CLIP, we use a background specific prompt:
A photo of a {label}, a type of background location", where label is the visual scene class from our proposed taxonomy. If a shot contains T frames, we utilize CLIP's visual encoder to extract frame-wise visual embeddings $v_{t}(t=1,...,T)$.
For each of the individual scene labels in our taxonomy, we utilize CLIP's text encoder to extract embeddings $e_{l} (l=1,2,...,L)$ for the background specific prompts
We use the label-wise (prompt-specific) text and frame-wise visual embeddings to obtain a similarity score matrix $S$, whose entries $S_{lt}$ are computed as follows:
\begin{equation}\label{simmatrixscore}
S_{lt}=\frac{e_{l}^{T}v_{t}}{\lVert e_{l} \rVert_{2} \lVert v_{t} \rVert_{2}}
\end{equation}
We compute an aggregate shot specific score for individual scene labels by temporal average pooling over the similarity matrix $S_{lt}$, since the visual content within a shot remains fairly unchanged. The computation of shot specific score called $\texttt{CLIPSceneScore}_{\texttt{l}}$ for $l$th visual scene label is shown as follows:
\begin{equation}
\texttt{CLIPSceneScore}_{\texttt{l}}=\frac{\sum_{t=0}^{T}(S_{lt})}{T}
\label{score pooling}
\end{equation}
|