
Why is it important?
Portrayals of risk behaviors (such as violence, sexual content and substance-abuse) sparks concerns about the potential side effects of repeated exposure. Particularly in the case of children and adolescents, where this exposure has been linked to increased risk for engaging in violence[1,2], smoke and alcohol consumption[3,4], and earlier sexual initiation[5]. With more movies being produced every year—more than 700 movies have been released each year since 2014[6]—producers and filmmakers should look into artificial intelligence to help them identify risk behavior portrayals.
What did we do?
We investigate the relation between the language used in movie scripts and the portrayals of risky behaviors. We believe that this approach can be used to provide filmmakers with an objective estimate of how violent/sexual a movie is, and help identify subtleties that they may otherwise not pick up on, suggesting appropriate changes to a movie script even before production begins.
How do you rate movie content?
We obtained a dataset of 989 Hollywood movies, from 12 different genres (1920—2016)[7]. Content ratings for violence, sexual and substance-abusive content were provided by Common Sense Media (CSM), a non-profit organization that promotes safe technology and media for children. CSM experts rate movies from 0 (lowest) to 5 (highest) with each rating manually checked by the executive editor to ensure consistency across raters. As targets for our models, we categorize these variables as LOW (\(<3\)), MED (\(=3\)), and HIGH (\(>3\)).
Identifying violent portrayals from what characters say
Martinez VR, Somandepalli K, Singla K, Ramakrishna A, Uhls YT, Narayanan S. Violence Rating Prediction from Movie Scripts. In: Proceedings of the AAAI Conference on Artificial Intelligence. 2019. page 671–8.
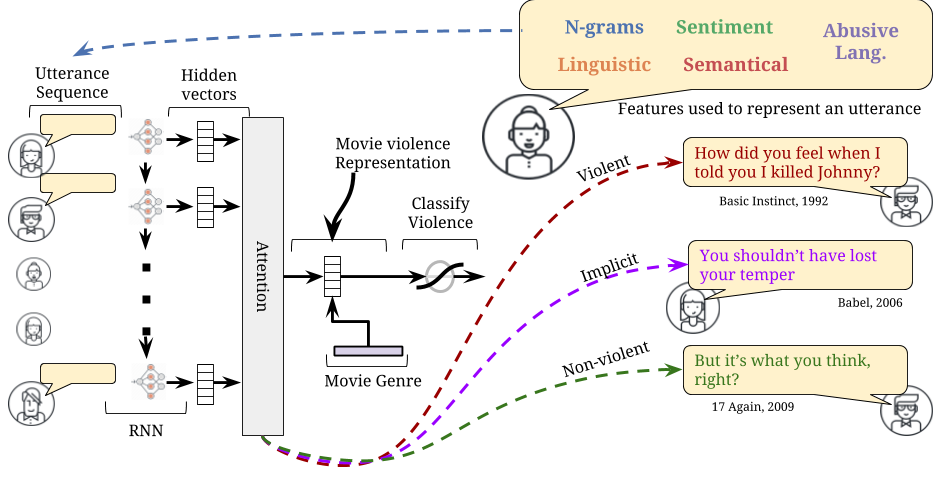 Figure 1. Recurrent Neural Network with attention that learns from the sequence of characters utterances. Post-hoc attention analysis reveals violent content in each utterance. These can be grouped into explicit, implicit, and non-violent.
Figure 1. Recurrent Neural Network with attention that learns from the sequence of characters utterances. Post-hoc attention analysis reveals violent content in each utterance. These can be grouped into explicit, implicit, and non-violent.
We realized that movie scripts can be expressed as a sequence of actors speaking one after, which leads to a natural formulation for a recurrent neural network (RNN).
Features
Each character utterance is represented by its linguistic attributes across five categories: N-grams[8], Linguistic and Lexical[9], Sentiment[10,11], Abusive Language[12] and Distributional Semantics[13]. We also consider movie genres as an additional (one-hot) feature since these are generally related to the amount of violence in a movie (e.g., romance vs. horror). This allows our model to learn that some utterances that are violent for a particular genre may not be considered violent in other genres.
Model Implementation
The RNN model was implemented using Keras. As hyper-parameters, we used the Adam optimizer with mini-batch size of 16 and learning rate of 0.001. To prevent over-fitting, we use drop-out of 0.5, and train until convergence (i.e., consecutive loss with less than \(10^{-8}\) difference). For the RNN layer, we evaluated Gated Recurrent Units[14] and Long Short-Term Memory cells[15]. Both models were trained with number of hidden units \(H \in {4,8,16,32}\).
Experiments
To measure the performance of our model, we compare against trained SVCs using lexicon based-approaches[16,12], a state-of-the-art model for implicit abusive language detection[8], and an RNN with deep-attention[17]. Although not common in most deep-learning approaches, we performed 10-fold cross-validation (CV) to obtain a more reliable performance estimation of each model.
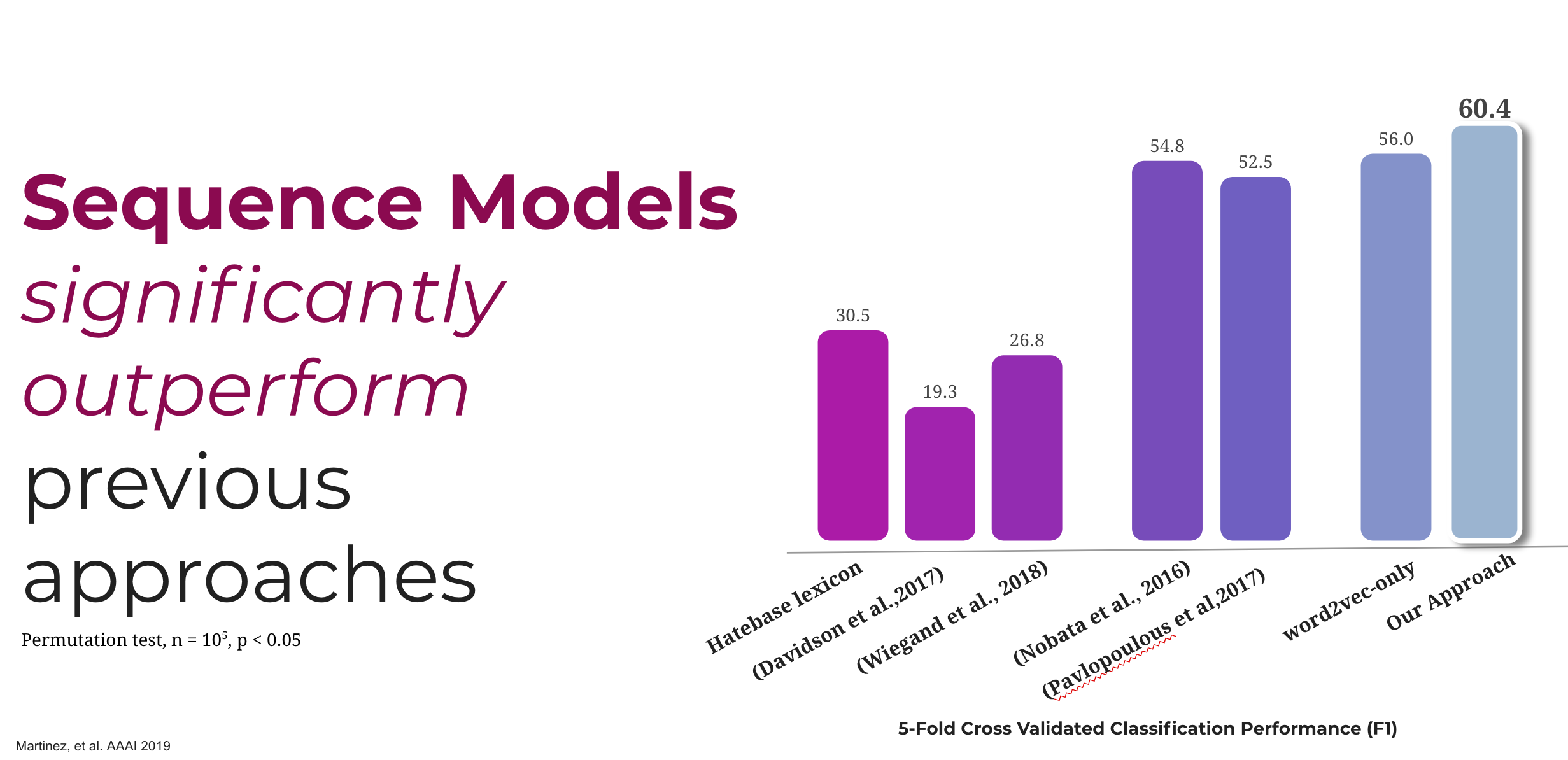 Figure 2. Results on predicting levels of violence from language used in movie scripts
Figure 2. Results on predicting levels of violence from language used in movie scripts
Results
Figure 2 shows the macro-averaged classification performance of baseline models and our proposed model. Our model performed better than the other models, with a significant difference in performance (permutation tests, \(n=105\), all \(p <0.05\)). The best performance is obtained using a 16-unit GRU with attention (GRU-16), which performed significantly better than the baselines (permutation test, smallest \(\Delta=0.056,n=105\), all \(p <0.05\)), and better than the RNN models trained on word2vec only (\(\Delta = 0.079, n= 105, p <0.05\)). The improvement over previous models can be attributed mostly to the inclusion of Sentiment features and Semantic representations (see Figure 3).
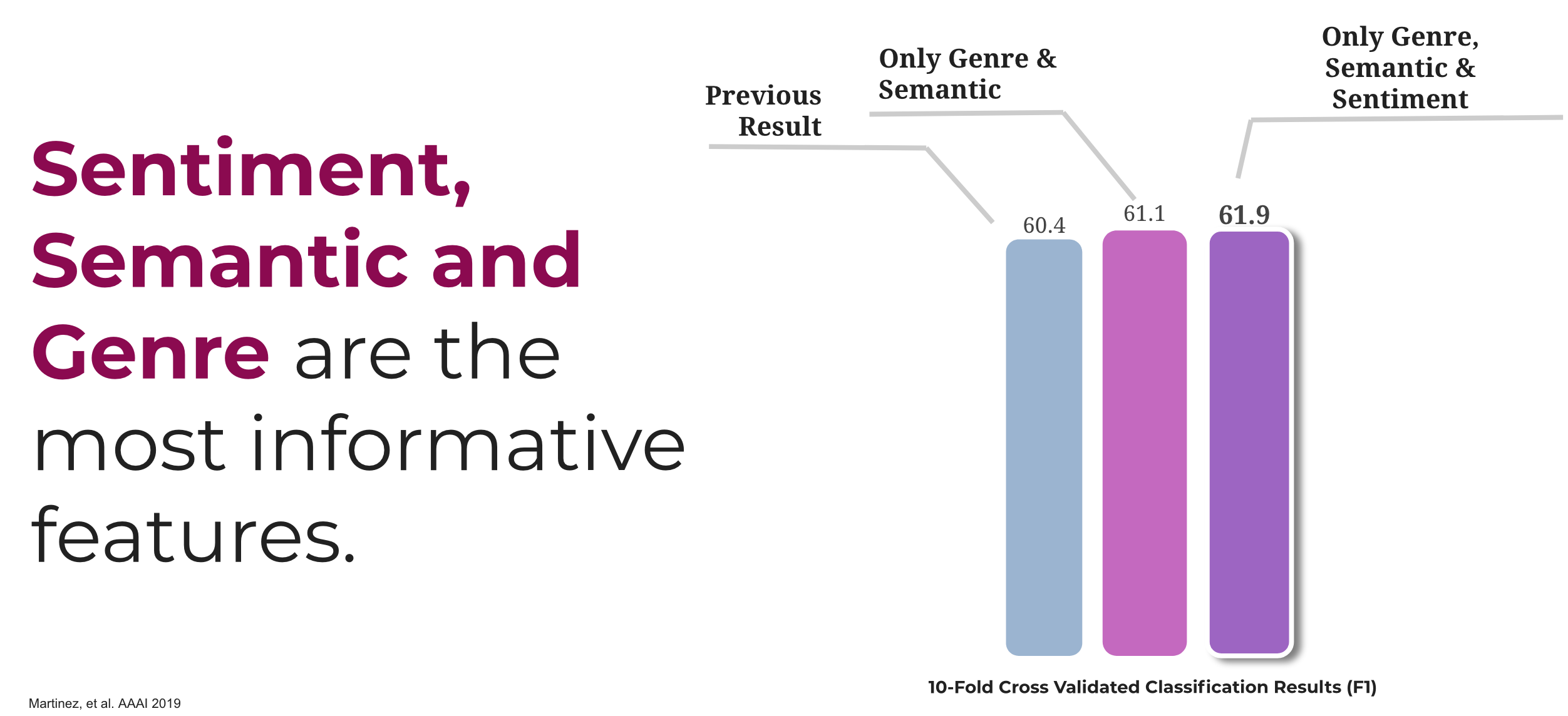 Figure 3. Ablation studies of violence rating prediction
Figure 3. Ablation studies of violence rating prediction
What about other risk behaviors?
Martinez V, Somandepalli K, Uhls Y, Narayanan S. Joint Estimation and Analysis of Risk Behavior Ratings in Movie Scripts. In: EMNLP. 2020.
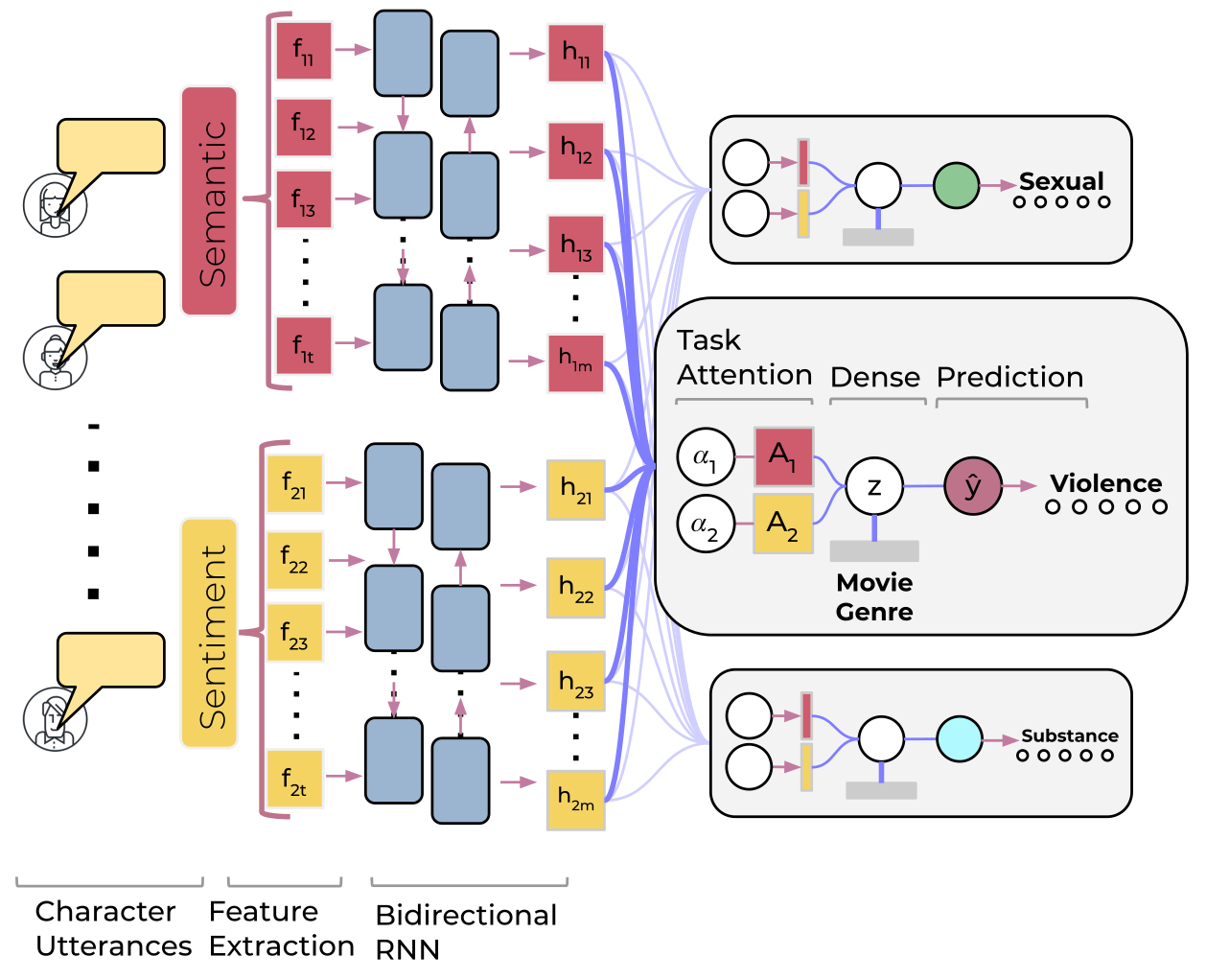 Figure 4. Multi-task model for risk behaviors detection: Each utterance is represented by semantic and sentiment features, fed to independent RNN encoders.The sequence of hidden states from the encoders serve as input for task-specific layers (gray boxes)
Figure 4. Multi-task model for risk behaviors detection: Each utterance is represented by semantic and sentiment features, fed to independent RNN encoders.The sequence of hidden states from the encoders serve as input for task-specific layers (gray boxes)
It’s not only about violence! Risk behaviors frequently co-occur with one another, both in real-life[18] and in entertainment media[19,20,21]. To capture the this co-occurrence, we develop a multi-task learning (MTL) approach to predict a movie script’s violent, sexual and substance-abusive content (see Figure 4). By using a multi-task approach, our model could improve violent content classification, as well as provide insights on its relation to other dimensions of risk behaviors depicted in film media.
Features
This time we decided to focus only on the features that were found to be important: semantic, sentiment and genre. Semantic representations were obtained using movieBERT, our own BERT[22] model (n=12; 768-dimensional) fine-tuned on over 6,000 movie scripts. We replaced the sentiment lexica with a neural representation obtained from a Bi-lateral LSTM trained on the related task of movie reviews. Finally, movie genres for each movie were obtained from IMDb.
Model Implementation
Our MTL model is implemented using Keras, trained with Adam optimizer (\(lr=0.001\)), batch size of 16, and high dropout probability (\(p=0.5\)). For the RNN layer, we once again used bi-directional GRUs[14]. For the sentiment models, we trained a Bi-LSTM parameters were: 50-dimensional hidden representation, dropout (\(p= 0.1\)), trained with Adam optimizer on a batch size of 25 and a L2-penalty of \(10^{-4}\).
Experiments
We compared the model with the violence prediction model[23], and variations of the MTL model under different semantic features with and without the multi-task paradigm.
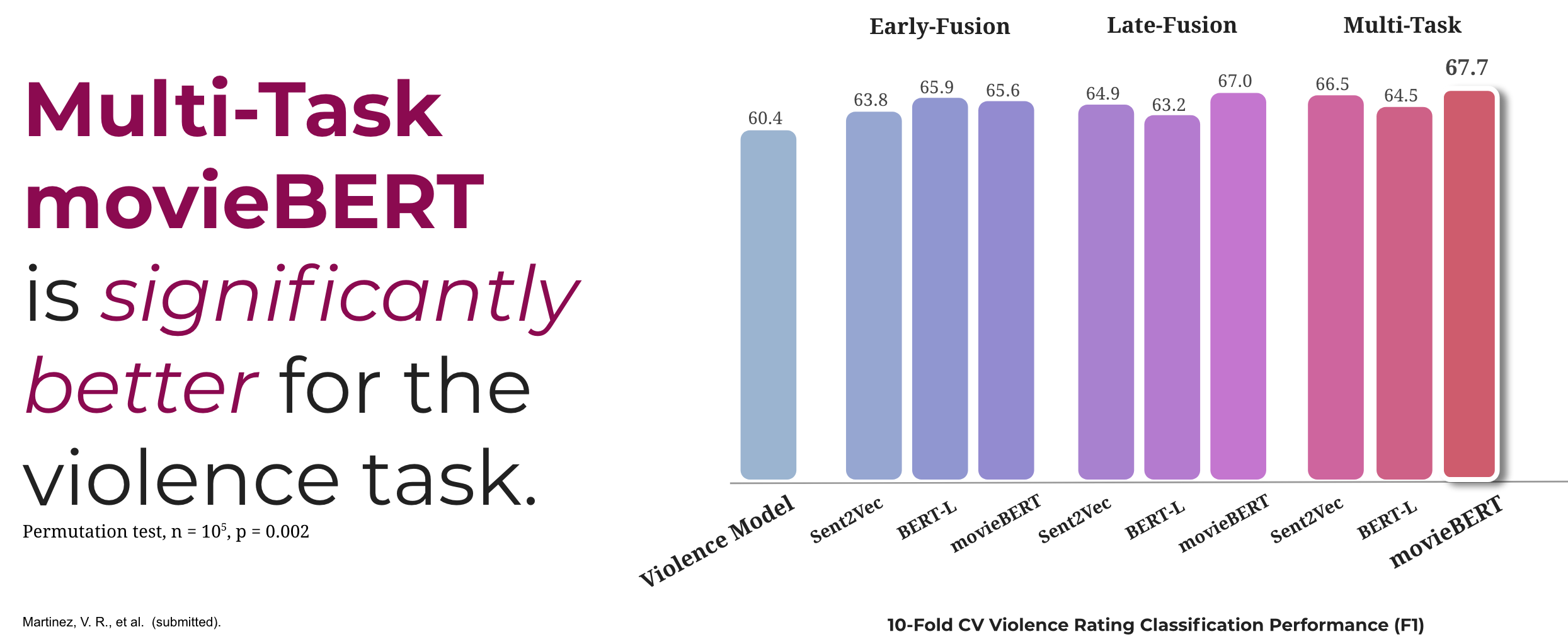 Figure 5. Results on predicting levels of violence from language used in movie scripts
Figure 5. Results on predicting levels of violence from language used in movie scripts
Results
Figure 5 presents the classification performance for the baselines and our second model. We see that just focusing on the important features (i.e., reducing the complexity of our feature set) increases prediction performance significantly (permutation test, \(n= 105\), all \(p <0.05\)). Including co-occurrence information, in the form of multiple tasks, gained an average \(F1= 1.22%\) points. The best model achieves \(F1= 67.7%\), outperforming the previous model for violent content rating prediction by a significant margin (perm. test \(n= 105,p= 0.002\)). Additionally, we found that the multi-task model is not only better at predicting violence, but also at detecting substance abuse (see Figure 6).
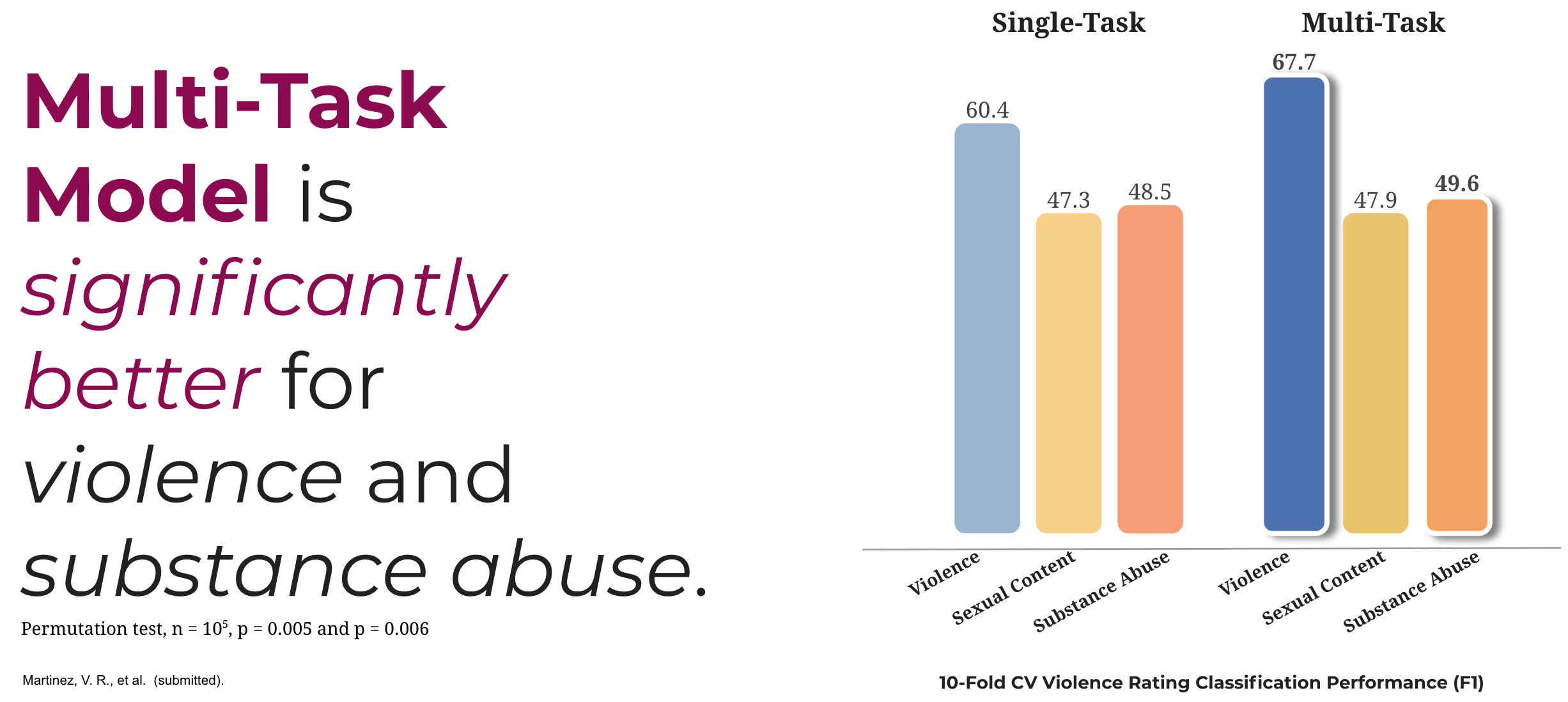 Figure 6. Single-Task vs. Multi-Task models
Figure 6. Single-Task vs. Multi-Task models
What does this all mean?
Our approach shows that computational models are capable of identifying risk behaviors from linguistic patterns found in movie scripts. Complementing audio-visual methods, our language-based models can be used to identify subtleties in the way risk behavior content is portrayed even before production begins and offer a valuable tool for content creators and decision makers in entertainment media.
Related Publications
-
Martinez, V. R., Somandepalli, K., Singla, K., Ramakrishna, A., Uhls, Y. T., & Narayanan, S. (2019, July). Violence rating prediction from movie scripts. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 33, pp. 671-678).
-
Martinez, V. R., Somandepalli, K., Uhls, Y. T., & Narayanan, S. (2020). Joint Estimation and Analysis of Risk Behavior Ratings in Movie Scripts. In Proceedings of EMNLP 2020.
References
- 1. Anderson CA, Bushman BJ. Effects of violent video games on aggressive behavior, aggressive cognition, aggressive affect, physiological arousal, and prosocial behavior: A meta-analytic review of the scientific literature. Psychological Science 2001;12(5).
- 2. Bushman BJ, Huesmann LR. Effects of televised violence on aggression. Handbook of children and the media 2001;:223–54.
- 3. Sargent JD, Beach ML, Adachi-Mejia AM, Gibson JJ, Titus-Ernstoff LT, Carusi CP, et al. Exposure to movie smoking: its relation to smoking initiation among US adolescents. Pediatrics 2005;116(5).
- 4. Dal Cin S, Worth KA, Dalton MA, Sargent JD. Youth exposure to alcohol use and brand appearances in popular contemporary movies. Addiction 2008;103(12).
- 5. Brown JD, L’Engle KL, Pardun CJ, Guo G, Kenneavy K, Jackson C. Sexy media matter: exposure to sexual content in music, movies, television, and magazines predicts black and white adolescents’ sexual behavior. Pediatrics 2006;117(4).
- 6. Watson A. Movie releases in North America from 2000-2018 [Internet]. Statista2019;Available from: https://www.statista.com/statistics/187122/movie-releases-in-north-america-since-2001/
- 7. Ramakrishna A, Martı́nez Victor R, Malandrakis N, Singla K, Narayanan S. Linguistic analysis of differences in portrayal of movie characters. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017. 2017.
- 8. Nobata C, Tetreault J, Thomas A, Mehdad Y, Chang Y. Abusive language detection in online user content. In: Proceedings of the 25th International Conference on World Wide Web. 2016.
- 9. Fast E, Chen B, Bernstein MS. Empath: Understanding topic signals in large-scale text. In: Proceedings of the Conference on Human Factors in Computing Systems, CHI 2016. 2016. page 4647–57.
- 10. Nielsen F Årup. A New ANEW: Evaluation of a Word List for Sentiment Analysis in Microblogs. In: Proceedings of the ESWC2011 Workshop on ‘Making Sense of Microposts’: Big things come in small packages. 2011. page 93–8.
- 11. Gilbert CJHE. VADER: A parsimonious rule-based model for sentiment analysis of social media text. In: Eighth International Conference on Weblogs and Social Media ICWSM 2014. 2014.
- 12. Wiegand M, Ruppenhofer J, Schmidt A, Greenberg C. Inducing a Lexicon of Abusive Words–a Feature-Based Approach. In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2018. 2018.
- 13. Mikolov T, Sutskever I, Chen K, Corrado GS, Dean J. Distributed Representations of Words and Phrases and their Compositionality. In: Advances in Neural Information Processing Systems. 2013. page 3111–9.
- 14. Cho KH, Merrienboer B van, Bahdanau D, Bengio Y. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. CoRR 2014;abs/1409.1259.
- 15. Hochreiter S, Schmidhuber J. Long Short-Term Memory. Neural Computation 1997;9(8):1735–80.
- 16. Davidson T, Warmsley D, Macy MW, Weber I. Automated Hate Speech Detection and the Problem of Offensive Language. In: Proceedings of the Eleventh International Conference on Web and Social Media, ICWSM 2017. 2017. page 512–5.
- 17. Pavlopoulos J, Malakasiotis P, Androutsopoulos I. Deeper Attention to Abusive User Content Moderation. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, EMNLP 2017. 2017. page 1125–35.
- 18. Brener ND, Collins JL. Co-occurrence of health-risk behaviors among adolescents in the United States. Journal of Adolescent Health 1998;22(3):209–13.
- 19. Bleakley A, Ellithorpe ME, Hennessy M, Khurana A, Jamieson P, Weitz I. Alcohol, Sex, and Screens: Modeling Media Influence on Adolescent Alcohol and Sex Co-Occurrence. The Journal of Sex Research 2017;54(8):1026–37.
- 20. Bleakley A, Romer D, Jamieson PE. Violent film characters’ portrayal of alcohol, sex, and tobacco-related behaviors. Pediatrics 2014;133(1).
- 21. Thompson KM, Yokota F. Violence, sex, and profanity in films: correlation of movie ratings with content. Medscape General Medicine 2004;6(3).
- 22. Devlin J, Chang M-W, Lee K, Toutanova K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1. Association for Computational Linguistics; 2019.